Tell CMake where to find the compiler by setting either the environment
variable "CUDACXX" or the CMake cache entry CMAKE_CUDA_COMPILER to the full
path to the compiler, or to the compiler name if it is in the PATH.
cmake가 쿠다 컴파일러를 찾지 못해서 발생한는 에러로 [1]을 참고해 아래와 같이 쿠다 경로만 지정해 주면 끝난다.
소명자료: 녹취록(사용안함), 의사표시 공시송달(단, 공시송달 확정일이 계약 해지일(2020.12.06)로부터 최소 1개월 전(최소 2020.11.06 이전에 확정이 되어야함) 이여야지 인정이 됨)
주택도시공사 전세보증에 가입된 상태(이거 없었으면 답이 없었을수도...)
사건내용은 이렇다.
약 2020.08.15쯤(확실하지 않음) 임대인에게 계약해지를 통보하기 위해 임대인에게 전화를 했지만, 전화에 응하지 않았다. 그 뒤 몇번 더 시도를 했지만 역시 전화를 받지 않았으며 어쩔 수 없이 내용증명을 우편으로 임대인 주소지로 전달하였는데, 반송이 되었다. 처음에는 주소가 잘못 되었나 생각했는데 집배원의 말에 의하면 집에 개소리가 들렸고 사람이 없는 집은 아닌것 같다고 했다. 그래서 반송된 내용증명을 바탕으로 의사표시 공시송달을 신청하였으며 그 후 공시송달(공시송달은 법무사를 통해서 신청을 하였다.)이 끝나기 전에 다행이 임대인이랑 연락이 되어서 급하게 녹취를 진행하였다. (임대인이 못 믿겨워서 공시송달은 그냥 두었다...) 임대인 사정을 들어보니 코로나때문에 임대사업이 망했다나 뭐라나... 그래서 빚이좀 있어서 연락을 잘 안받고 도망다니는? 신세로 보였다;; 아무튼 이런저런 말을 하는데 결론은 돈이 없어서 보증금을 못 돌려주겠다는 거고... 하지만 다행이 주택도시공사 전세보증에 가입이 된 상태이고, 보증금을 받으려면 진행절차 중 가장 중요한 임차권등기명령을 신청해야 한다고 해서 이렇게 신청하기에 이르게 되었다. (살면서 이런일도 다 있더라...)
처음에는 인터넷으로 신청을 하려고 했으나 집에 프린터기, 스캐너(사진으로 찍으면 되지만 제일 중요한 문서출력이 안된다.)도 없고 이상하게 전사소송사이트를 접속하려고 하면 보안시스템이 충돌나는지 보안프로그램을 설치해도 계속 문제가 생겨서 그냥 직접 지방법원에 가서 서류를 작성하기로 마음먹었다...
처음에는 복잡할 줄 알았지만 1시간 내로 금방 할 수 있는 내용이고 인터넷으로 혼자 모르는 용어랑 시름하는 것 보다는 직원에게 물어봐서 정확하고 빠르게 진행을 할 수 있어서 인터넷보다는 그냥 시간좀 내서 관할 지방법원에 찾아가는게 더 좋다고 생각한다. (물론 돈만있으면 가장 좋은건 법무사에게 맏기면 되지만...)
준비해야할 서류는 다음과 같다.
1. 등본 또는 초본(주소가 나와야함)
2. 부동산 등기부등본(이건 법원가서 해도되고 아니면 동사무소 또는 인터넷 또는 무인기기에서 출력이 가능하다.)
3. 임대차계약서
4. 소명자료(나의경우 공시송달관련 자료를 첨부함)
5. 신분증
이정도면 되고 나머지는 직접가서 펜으로 작성하면 된다. 작성하는 항목도 어렵지않고 모르면 그냥 물어보면 된다. 그리고 등록세, 송달료등 결제가 필요하기 때문에 5만원 정도 적당히 준비해서 가면 된다.
신청에는 무리가 없었고(법원거리가 멀어서 좀 고생했지만...) 다른 게시글을 보니깐 도면을 첨부하는 사람도 있던데 도면은 필수가 아니라 선택이라서 없어도 상관 없다고 한다. 그리고 처음에는 공시송달처럼 법무사에게 맞기려고 했는데 가격이 좀 생각보다 비싸서;; 막상해보면 그 가격이 나올리가 없는데,,, 이번일로 다음에 비슷한 일이 터지면 그냥 직접하는게 좋다고 생각한다.
추가로 주택보증공사에서는 계약일이 끝나고 1개월뒤 보증금을 못받을 때 보증사고로 본다고 하는데 이때 법원에서 온 임차권등기명령 서류를 가지고 있다가 1개월 뒤 이행청구를 진행하면 된다고 한다.
추가로 신청을하고 하루정도 지난다음 나의 사건검색 에서 등기명령 신청후 법원에서 받은 사건번호를 검색하면 접수가 잘 되었는지 확인이 가능하다. 사건번호를 잊어버렸다면 송달료를 결제한 영수증에 있는 은행번호로 송달료 조회 로 사건번호를 찾을 수 있다.
이 글은 ray 도큐먼트(document)[1]를 바탕으로 요약 정리 및 코드 실행 결과를 적어놓은 글이다.
ray 프레임워크(framework)는 분산 어플리케이션을 구축할 수 있도록 도와주는 API이다. 내가 ray를 공부하기 시작한 이유는 당연히 분산처리를 해야할 데이터가 생겼기 때문이다. 분산처리 프레임워크로 윈도우에서는 현재 이슈가 좀 있지만 공식적으로 윈도우도 지원하며 언어는 파이썬과 자바를 지원한다.
분산처리를 도와주는 프레임워크이기에 분산처리를 이용할 수 있는 곳이면 어디든지 사용이 가능하다 예로
하이퍼파라메터(hyperparameter)를 튜닝할때 그리드 서치(grid serach)를 이용한다고 가정 한다면 찾고자 하는 값의 범위나 모델의 크기에 따라서 다르지만 보통 많은 시간을 투자해야한다. 이때 병렬로 처리를 하면 무척 빠르게 값을 찾는 게 가능할 것이다[2].
강화학습(reinforcement learning)에서는 설정한 환경에 따라서 많은 탐색(exploration)을 해야하는 경우가 있고 때에따라 보상(rewad)을(를) 제대로 받지 못할 수도 있다. (주로 상황에따른 보상을 제대로 설정하지 않아서 의도치않은 상황이 발생하는 경우도 있다.) 그러면 학습속도가 굉장히 느려지는 경우가 발생하는데 이때 조금 억지스럽지만 환경 및 액션 설정들을 바꾸기가 힘들고 이대로 학습을 계속 진행해야 하는 상황 이라면 A3C같은 병렬처리 강화학습 알고리즘을 고려할 수 있다.
tensorflow 나 pytorch로 모델을 만들고 학습을 진행할때도 병렬로 학습을 진행할수도 있다. 이경우 만약 그래픽카드가 한컴퓨터에 여러개 붙어있는 경우라면 유명한 apex[3]를 사용해 GPU를 효율적으로 활용 할 수도 있지만 여러 컴퓨터가 물리적으로 분리가 되어있는 상황에서 ray를 활용하면 여러 컴퓨터에서 병렬처리를 할 수가 있다.
tensorflow나 pytorch로 모델을 만들었다면 이제 서빙(serving)을 해야한다. 이때도 ray를 활용하여 병렬적으로 처리를 진행할 수도 있다. 아니면 상황에 따라서 도커를 이용해 컨테이너화를 진행하고 오케스트레이션을 통해서 진행하는 방법도 있다.
일반적으로 ray를 사용한다면 다음 6가지 함수를 기억하고 넘어가면 좋다.
ray.init() => ray 컨텍스트(context) 초기화를 진행한다.
@ray.remote => 병렬처리를 위한 ray만의 파이썬 데코레이터(decorator)로 기본적으로 함수에 붙여서 사용하며 클래스(class)에 붙여서 사용하면 액터(actor)라고 부른다.
.remote() => @ray.remote 데코레이터를 붙였다면 언제든지 호출을 할수가 있으며 .remote()를 호출한 함수에 인자(argument)를 던져줄때 .remote()에 대신 던져준다.
ray.put() => 오브젝트 저장소(object store)에 받은 인자값을 저장하며 이때 오브젝트의 특정한 ID값을 던져준다. 이 기능은 같은 인자를 반복적으로 넘길때 오버헤드를 줄여주는 특별한 기능을한다.
ray.get() => 오브젝트의 ID값에 해당하는 값을 돌려준다. 이 함수가 호출될 때 비로소 분산처리가 시작되며 연속적으로(sequential) ray.get()을 지정했다면 선 ray.get() 작업이 끝날때 까지 뒤 작업들은 기다리게 된다.
ray.wait() => .remote()로 지정된 오브젝트들 중에서 준비가 된 오브젝트의 ID를 돌려준다.
*지금부터 시작할 모든 실습은 모두 도커에서 진행하였다.
팁 1: ray.get의 사용의 주의
ray.get()을 잘못 사용하는 경우 발생할 수 있는 문제에 대해서 다룬다.
시작하기전 간단한 지연 함수를 만들어서 테스트를 해본다. 아래 코드1 은 파이썬의 지연함수 time.sleep(1)를 사용해서 do_some_work(x)를 부를때마다 1초 지연하는 코드이다.
# 코드 1
import time
from datetime import datetime
def do_some_work(x):
time.sleep(1) # 1초 지연.
return x
start = datetime.now()
results = [do_some_work(x) for x in range(4)]
print("duration =", datetime.now() - start)
print("results = ", results)
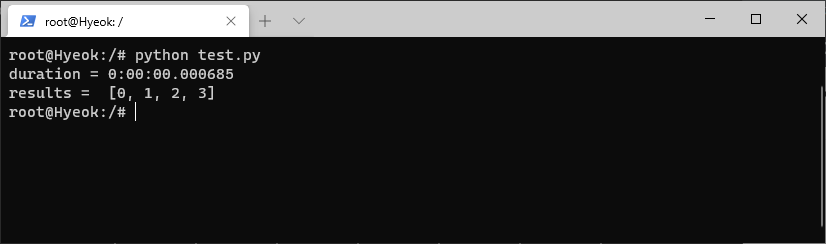
코드 1의 결과 대략 4초가 걸린다
코드 1의 결과를 보면 예상대로 대략 총 4초가 나왔다. 이제 ray를 통한 병렬처리로 시간을 단축해보겠다. 시작전 잘못된 사례를 살펴보겠다. 아래 코드 2는 ray.get()의 사용의 잘못된 예의 코드이다.
# 코드 2
import time
from datetime import datetime
import ray
ray.init() # ray 컨텍스트 초기화
@ray.remote
def do_some_work(x):
time.sleep(1) # 1초 지연.
return x
start = datetime.now()
results = [ray.get(do_some_work.remote(x)) for x in range(4)]
print("duration =", datetime.now() - start)
print("results = ", results)
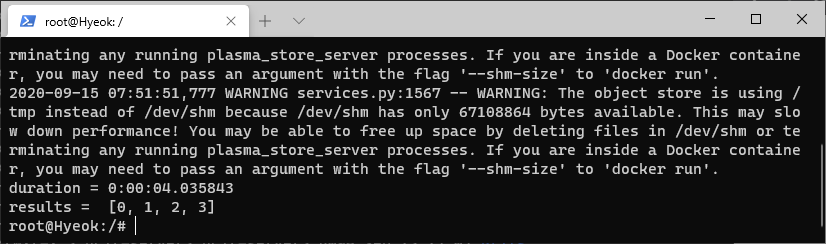
코드 2의 결과 대략 4초가 걸린다(위의 오류는 도커에서 실행해서 발생한는 오류로 지금 진행할 내용들은 전부 단순 튜토리얼 이니 신경쓸필요 없다.)
코드 2의 결과는 코드 1의 결과랑 비슷함을 알수가 있다. 그러나 만약 병렬 처리를 하고싶다면 이런 결과는 원치 않을것 이다. 문제는 ray.get()을 호출할때 연속적으로 for문을 통해서 호출을 해준것이 문제이다. 이렇게 연속적으로 ray.get()을 호출하게 되면 나중에 호출된 ray.get()은 앞서 호출된 ray.get()의 작업이 끝날때 까지 기다리게 된다. 그래서 순차적으로 ray.get()을 호출하지말고 병렬처리하고 싶은 함수나 클래스에 .remote()를 불러주고 ray.get()은 한번만 호출한다고 생각하면 된다. 아래 코드 3이 올바른 ray.get()의 사용법이다.
# 코드 3
import time
from datetime import datetime
import ray
ray.init() # ray 컨텍스트 초기화
@ray.remote
def do_some_work(x):
time.sleep(1) # 1초 지연.
return x
start = datetime.now()
results = [do_some_work.remote(x) for x in range(4)]
results = ray.get(results) # ray.get()은 한번만 불러준다.
print("duration =", datetime.now() - start)
print("results = ", results)
코드 3의 결과 대략 1초가 걸린다.
코드 3의 결과를 보면 대략 1초안에 4초짜리 프로세스를 병렬로 진행하였다.
팁 2: 매우 작은 작업에는 ray는 오히려 독이된다.
ray는 기본적으로 분산처리를 위한 프레임워크이다. 이 말은 여러개의 프로세서들을 통제하기 위해서 스케줄링, 프로세스간 커뮤니케이션, 시스템 상태 업데이트등 많은 추가적인 작업이 들어간다. 그래서 만약 저 위해서 했던 간단한 작업은 1초짜리지만 0.1밀리세컨드로 줄인다면(해야할 작업이 ray의 준비 작업시간보다 빠르다면)이는 오버헤드가 걸렸다고 하며 옳지못한 결과를 보게 된다. 코드 4는 코드1의 1초 부분을 0.0001초로 바꾼 것 이다.
# 코드 4
import time
from datetime import datetime
def do_some_work(x):
time.sleep(0.0001) # 0.1밀리세컨드 지연.
return x
start = datetime.now()
results = [do_some_work(x) for x in range(4)]
print("duration =", datetime.now() - start)
print("results = ", results)
코드 4의 결과 0.6밀리세컨드가 걸린다.
코드 4의 결과를 보면 실행에 대략 0.6밀리세컨드가 걸렸다. 과연 이 작업을 ray를 이용해 병렬로 처리할때 더 빠르게 처리를 할 수 있을까? 코드 5는 코드 3의 1초 지연을 0.0001초로 바꾼 것 이다.
# 코드 5
import time
from datetime import datetime
import ray
ray.init() # ray 컨텍스트 초기화
@ray.remote
def do_some_work(x):
time.sleep(0.0001) # 0.1밀리세컨드 지연.
return x
start = datetime.now()
results = [do_some_work.remote(x) for x in range(4)]
results = ray.get(results) # ray.get()은 한번만 불러준다.
print("duration =", datetime.now() - start)
print("results = ", results)
코드 5의 결과 대략 19.3밀리세컨드가 걸린다.
코드 5의 결과를 보면 실행에 대략 19.3밀리세컨드로 오히려 더 오래걸린다. 이 처럼 가벼운 작업에 있어서는 그냥 ray없이 그냥 사용하는 편이 더 나을수도 있다.
팁 3: 같은 오브젝트를 .remote()에 반복해서 넘길때는 ray.put()을 명시적으로 사용하자.
병렬처리를 하는데 있어서 같은 오브젝트를 동시에 실행하고 싶다고 가정 해본다. 그러면 자연스럽게 처리에 사용할 오브젝트를 복사해서 동시에 실행해야 되지 않을까 하는데 쓰는 작업이 있다면 모를까 읽기 작업에 있어서는 사용할 오브젝트를 복사해서 전달해줄 필요가 전혀없고 하나의 오브젝트만 전달해서 공유해 사용을 할수가 있다. 이때 ray.put()이 힘을 발휘한다. 코드 6은 numpy로 만든 비교적 큰 오브젝트를 연속해서 넘기고 있다.
# 코드 6
from datetime import datetime
import numpy as np
import ray
ray.init() # ray 컨텍스트 초기화
@ray.remote
def no_work(x):
return
start = datetime.now()
x = np.zeros((5000, 5000))
results = [no_work.remote(x) for x in range(20)]
results = ray.get(results)
print("duration =", datetime.now() - start)
코드 6의 결과 대략 2초가 걸린다.
일반적으로 코드 6과 같이 작성을 하면 ray는 내부적으로 ray.put()을 여러번 부르게 되고 병렬처리에 있어서 오브젝트를 계속 복사하는데 많은 시간을 사용하게된다. 이때 이를 방지하기 위해서 코드 7과 같이 명시적으로 ray.put()을 한번만 호출하여 리턴된 오브젝트 ID값을 .remote()의 인자로 넘겨주면 된다.
# 코드 7
from datetime import datetime
import numpy as np
import ray
ray.init() # ray 컨텍스트 초기화
@ray.remote
def no_work(x):
return
start = datetime.now()
x = ray.put(np.zeros((5000, 5000))) # 오브젝트 ID x를 .remote()에 넘긴다.
results = [no_work.remote(x) for x in range(20)]
results = ray.get(results)
print("duration =", datetime.now() - start)
코드 7의 결과 대략 89.8밀리세컨드가 걸린다.
코드 7에서 단순히 명시적으로 ray.put()을 호출해준것 밖에 없는데 확실히 성능이 눈에띄게 좋아졌다.
팁 4: ray.wait()을 적극 활용해 병렬 파이프라인 처리의 특징을 최대한 활용하자.
팁 1 에서는 모든 프로세스가 같은 처리 시간을 갖는다고 가정을 했고 ray.get()을 한뒤 그 후 처리에 있어서는 언급을 안했다. 만약 모든 프로세스가 다른 처리 시간을 갖는다고 가정하면 팁 1에서는 빠르게 동작 할지라도 마지막 가장 늦은 프로세스가 끝날때 까지는 기다려야 한다. 그후 값을 돌려받고 다음 처리를 진행하게 되는데 이때 처리가 빨리 끝나는 프로세스값을 먼저 받아서 먼저 처리를 하면 그 성능을 더욱 극대화 할수가 있다. 빨래를 3번 걸쳐서 진행한다고 할 때 첫 번째 세탁물의 세탁이 끝나고 건조 중일 때 다음 세탁물은 이전 세탁물의 건조가 끝날 때 까지 기다 지리 않고 계속해서 세탁을 계속 진행할 수가 있듯이 말이다. 이 과정에서 누가 먼저 끝났는지 알기 위해서 ray.wait()을 사용한다. 먼저 코드 8은 연속균등분포(uniform distribution)에서 0 ~ 4 사이 랜덤으로 샘플링해 지연을 한다. 그리고 병렬 파이프라인 처리 활용의 효과를 보이기 그 뒤 지연 작업인 process_results를 추가로 넣는다.
# 코드 8
from datetime import datetime
import time
import random
import ray
ray.init()
@ray.remote
def do_some_work(x):
time.sleep(random.uniform(0, 4)) # 0 ~ 4초 사이 램덤으로 지연
return x
def process_results(results):
sum = 0
for x in results:
time.sleep(1)
sum += x
return sum
start = datetime.now()
datas = ray.get([do_some_work.remote(x) for x in range(10)]) # 이 작업은 대략 4초 안으로 걸린다.
results = process_results(datas) # 이 작업은 대략 10초 정도 걸린다.
print("duration = ", datetime.now() - start)
print("results = ", results)
코드 8의 결과 대략 13초가 걸린다.
코드 8의 결과는 do_some_work의 4초 안으로 걸리는 결과와 process_results의 10초 정도 걸리는 결과를 생각해 볼때 대략 13초 정도가 나온다. 하지만 이 결과는 최선의 결과가 아니다. 왜냐하면 do_some_work가 전부 4초대를 내놓는 작업이 아니라 1초보다 빠른 작업을 내놓는 작업이 있을수도 있다. 그러면 우리가 할 일은 단순 합을 구하는 작업이니 모든 작업이 끝날때까지 기다릴 필요가 전혀없고 끝난 프로세스먼저 결과를 가져와 더하면 된다. process_results는 1초 지연 작업이 있기에 이는 현명한 방법이다. 이를 위해서 코드 9처럼 누가 먼저 끝났는지 ray.wait()으로 수시로 확인을하고 값을 가져오고 처리하면 된다.
# 코드 9
from datetime import datetime
import time
import random
import ray
ray.init()
@ray.remote
def do_some_work(x):
time.sleep(random.uniform(0, 4)) # 0 ~ 4초 사이 램덤으로 지연
return x
def process_results(sum, result):
time.sleep(1)
sum += result
return sum
start = datetime.now()
datas = [do_some_work.remote(x) for x in range(10)]
sum = 0
while len(datas):
done, datas = ray.wait(datas) # 다된 작업은 done으로 넘긴다.
sum = process_results(sum, ray.get(done[0]))
print("duration = ", datetime.now() - start)
print("results = ", sum)
코드 9의 결과 대략 10초가 걸린다.
코드 8과 코드 9는 거의 같지만 코드 9처럼 먼저 끝나는 작업을 먼저 처리하는 방식이 더욱더 효율적임을 확인할 수 있다.